この記事を読むのに必要な時間は約 14 分です。
ブログ記事を書くに当たって他のブログがどのような記事を書いているかを調べるのは重要です。
ライバルがどのような戦略を取っていてどのような記事を書いているか。
今回他者のブログを調べるに当たって、今後記事を増やしていこうと思っているプログラミング分野の記事を記載している人をターゲットにして分析を行いました。
それも純粋に技術を追求しているブログではなく、解説やチュートリアルなどに特化しているブログが個人的には理想に感じていたため、その感覚に合う「DAIさん」と「マナブさん」のブログの記事を調べてみることにしました。
両者とも技術だけでなく、マーケティングや旅行、キャリア感などバランス良く記事が書かれているのでどのようなカテゴリーでどのような記事を書いているのかを参考にしようと思いこの2人のブログを調査しました。
スクレイピングで調べる内容
ざっくりと「記事タイトル」「カテゴリー」について調べてみることにしました。
それぞれを調べることで以下のように活用できます。
- 記事タイトル → SEO対策
- カテゴリー → サイト設計
PV数なども確認できるとさらに良いのですが、スクレイピングではそこまでの情報を取得できないため、ざっくりと全体の構造が見れれば良いと考えています。
記事タイトルを調べる目的
記事タイトルはSEOの対策や自然検索からの流入を増やすために重要です。
自身の記事を検索上位に持っていくために必要なことは多々ありますが、実際上位の表示されたときにクリックしてもらえるかどうかはタイトルが決め手となります。
タイトルを読んで「調べていることの答えがこの記事に書いてありそう」ということがわからないとクリックしてもらえません。
例えばこの記事の場合は「PythonとGoogle Colaboratoryでスクレイピングをしたい人」をターゲットにしていてこの記事を読めばやりたいことができそうであることを記事タイトルで伝えています。
カテゴリーを調べる目的
カテゴリーの分け方はブログを作成する上で非常に重要です。
SEOの観点ではGoogleに記事のまとまりを伝えることができます。
例えば「Python」というカテゴリーの記事が豊富にあれば、Googleからは「このサイトはPythonについて詳しく記載してある」と判断されると行ったことです。
また、実際にGoogleなどで検索して流入してきた人に対しても、類似した記事を確認するなどサイト内の回遊性を高めることができ、SEOの指標の一つでもある「ページ/セッション」を上げたり、直帰率の低下に繋げることもできます。
そのため、ブログを作成する際には事前にロールモデルとなるサイトでどのようなカテゴリー分けをしているかを調べておくことでカテゴリーの精査とサイトの方向性を決定することができます。
カテゴリーの分け方を途中で変更するのはなかなか労力がいるため、最初の枠作りが重要です。
また、今回は上記の情報に加えて記事のURLと投稿日時(更新日時)についても抜き出してみます。
PythonとColaboratoryでスクレイピングを行う
今回はブラウザ上でPythonが実行できるGoogle Colaboratoryを用いて対象のブログの記事一覧を抜き出します。
この組み合わせで行うことでPythonの環境構築が不要で、初心者でも簡単にスクレイピングを行うことができます。
- Pythonの環境構築が不要
- ネットさえあればどの端末からでもアクセス可能
- スクレイピングした結果をGoogle Driveへ保存するのも簡単
Google Colaboratoryの準備
Google Driveから新規ファイルを追加します。
「新規」ボタン、または右クリックから「Colaboratory」を選択します。

初めてColaboratoryを利用する場合は、その他に表示されていないと思うので「アプリを追加」からColaboratoryを追加してください。
「colabo」と検索すると表示されるので追加して使えるようにしてください。

すると、以下のような感じで新しいファイルが作成されるはずです。
このカーソルが当たっている場所にPythonのコードを書いて左側の三角の実行ボタンをクリックすることでコードを実行できます。

試しに以下のコードを記述して実行ボタンをクリックしてみてください。
print('Hello Colaboratory')以下の画面のようにコードを書いた下に「Hello Colaboratory」と表示されれば成功です。

PythonのBeautifulSoupでスクレイピング
Colaboratoryが利用できるようになったので実際にPythonを用いてスクレイピングを行なっていきます。
スクレイピングにはBeautifulSoupを利用します。
早速ですが、実際のソースを記載しておきます。
# for スクレイピング
from urllib.request import urlopen
from bs4 import BeautifulSoup
import pandas as pd
# 出力フォーマットの定義
columns = ['title', 'category', 'date', 'url']
df = pd.DataFrame(columns=columns)
# スクレイピング先URL
# url = 'https://manablog.org/'
url = 'https://dividable.net/'
# 複数カテゴリ付いている場合に分割する
def fetchCategories(categories):
categoriList = []
for category in categories:
categoriList.append(category.text)
return ' '.join(categoriList)
# ブログ記事取得
def getTargetPageData(targetUrl):
print(targetUrl)
html = urlopen(targetUrl)
soup = BeautifulSoup(html, 'html.parser')
entries = soup.find_all('div', class_='col-xs-12 wrap')
global df
for entry in entries:
se = pd.Series([
entry.find('h2').find('a').get('title'), #title
fetchCategories(entry.find('p', class_='cat').find_all('a')), #category
entry.find('time').text, #date
entry.find('h2').find('a').get('href') #url
], columns)
df = df.append(se, columns)
nextPage = soup.find('div', class_='pull-right')
nextPageUrl = nextPage.find('a')
if nextPageUrl:
getTargetPageData(nextPageUrl.get('href'))
else:
print('Done')
if __name__ == '__main__':
getTargetPageData(url)
# 取得したデータを表示
df
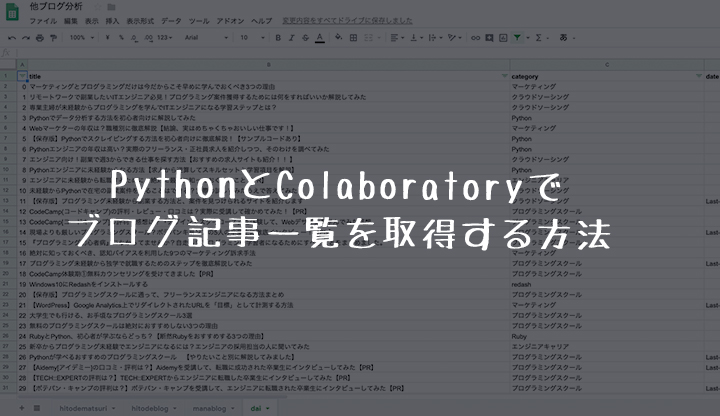
このコードをColaboratory上で実際に実行すると以下のような結果が表示されます。

最初にURLが表示されているのは記事を読みに行っているページです。
上記の結果はDAIさんのブログ記事を取得しているのですが、1ページに10記事×8ページ分(80記事弱)取得しています。
取得したデータは整形された状態で下に表示されています。
今回取得しているのは、「タイトル」「カテゴリ」「投稿(更新)日付」「記事URL」の4つです。
実際に実行するとわかりますが、ちゃんと全記事が取得できているはずです。
しかしこのままではColaboratory上に表示されるだけです。
次はここで表示したデータを実際にファイルとして保存する処理を追加していきます。
Colaboratoryの結果をCSV形式でGoogleDriveに保存する方法
以下のコードを追記してください。
「downloadToGoogleDrive」はその名の通りGoogleDriveにファイルを保存する方法です。
この関数を実行すると、マイドライブ直下に「dai.csv」というファイル名でスクレイピングで取得した記事一覧が保存されるようになります。
def downloadToGoogleDrive(df):
# for download to Google Drive
from google.colab import drive
drive.mount('/gdrive')
# Google Driveに保存
with open('/gdrive/My Drive/dai.csv', 'w', encoding = 'utf-8-sig') as f:
df.to_csv(f)また、Googleドライブに保存するに当たって、認証処理が必要になります。
実際上記のコードを実行すると、以下の画像のようにアクティベーションを求められます。

表示されたURLをクリックすると、Googleのログイン画面が表示されるので使用するアカウントを選択してください。

するといつものように確認画面が表示されるので「許可」をクリックしてください。

ログインが完了すると、認証コードが表示されるのでこれをコピーしてColaboratoryに入力してください。

すると認証が完了してGoogleドライブへの保存が可能となります。
呼び出し部分のコードは念のために貼っておきます。
先ほど関数の定義をこのif文より上に記述しておいてください。
if __name__ == '__main__':
getTargetPageData(url)
# 取得したデータを表示
df
# Googleドライブへ保存
downloadToGoogleDrive(df)
Colaboratoryの結果をCSV形式でダウンロードする方法
先ほどGoogleドライブへ保存する関数を定義したようにローカルにダウンロードする関数を定義します。
※if文より上に記述してください。
def downloadToLocal(df):
# for download to local
from google.colab import files
# ローカルにダウンロード
df.to_csv('df.csv')
files.download('df.csv')
この関数はGoogleドライブへの保存時とは違って特に認証は必要ありません。
しかし、ファイル容量が大きい場合などはダウンロードに失敗することなどもあります。
そういった場合にはGoogleドライブへ保存する処理に変更するようにしてください。
記事一覧が上手く取得できない場合
サイトの構造が違う場合、上記のコードをコピーしただけでは動作しないです。
コードの解説を下記noteで行なっているため、下記を読むことでコードを修正してほぼほぼ全てのサイトの記事一覧が取得できるようになるはずです。
もし、下記のnoteを読んでも上手くいかない場合はTwitterでDMなどを送ってくだされば個別に対応します。
※実際にヒトデさんの「ヒトデ祭り」や「hitodeblog」も記事一覧を抽出しましたが、少しコードの修正が必要でした。
取得したデータの活用方法
取得したデータはCSV形式のため、Excelに読み込んだり、スプレッドシート上に書き出すこともできます。
僕自身今回取得したデータは全てスプレッドシート上で管理しています。
スプレッドシートであれば、フィルタをかけたり、スプレッドシートの関数でカテゴリ毎の記事数を抽出することも簡単です。

取得したデータを活用してマーケティングの戦略に役立てるなりしてみてください。

