この記事を読むのに必要な時間は約 22 分です。
LINE Bot作りにハマっています。現在は使いやすい言語やサービスが豊富なのでサクッといろんなボットが作成できて良いですね。文字起こしも機械学習を利用した機能になりますが、これもGoogleやMicrosoftの提供しているAPIを利用することで無料で作成できます。
詳細のソースコードなどはnoteで公開予定ですが、大まかなロジックを本記事で紹介します。
※note公開しました。
とりあえず作ったもの公開
GoogleとMicrosoft両方のAPIでそれぞれ作ったのですが、一旦Google版を公開しておきます。友達追加して使ってみてください。
![]()
QRコードは以下

※返答がなければ時間を置いてから試してみてください。(無料アカウントで作成しているので利用回数に制限があります。)
これ、プログラムの経験が無い方からするとすごい複雑な処理をしているように思われるかもですが、かなり簡単に作れます。それこそ初心者にも作成可能です。
「LINE Botを作ってみたい。」
という方にはちょうど良いと思います。ここで作成したLINEボットの作成手順はnoteで公開予定です。公開したら追記しますね。
文字起こしボットとは
LINEで友達追加して利用するLINEボットで、文字を含む画像を送信すると、画像内の文字をテキスト形式で返してくれます。
利用シーンとしては、書籍を参考文献として引用したい場合などに利用します。今まで書籍の文章などは、本を観ながら文字を書き起こしていましたが、それが写真を撮って送信するだけで済むという便利なものです。
画像から文字を起こす技術はOCR(Optical Character Recognition)と呼ばれる技術(日本語だと光学式文字認識)で機械学習の一種ですが、それが個人でも簡単に実装が可能となっています。LINE Bot自体も簡単に作れるようになっているのでなんとも便利な時代ですね。
OCRのAPIはいくつかの企業が公開していますが、今回はGoogleが提供している「Cloud Vision API」とMicrosoftが提供している「Computer Vision API」を利用してLINEボットを作成しています。
LINE Botとは
LINEボットというのはLINEで友達追加して利用するあれです。有名なやつだと、郵便局の「ポスくま」とかヤマト運輸のボットですね。
 郵便局の再配達依頼がLINEだけで手続き完結!郵便局公式LINEアカウント「ぽすくま」が超便利!!
これらは企業が運営している公式のボットですがLINEボットは個人でも作成が可能となっています。
郵便局の再配達依頼がLINEだけで手続き完結!郵便局公式LINEアカウント「ぽすくま」が超便利!!
これらは企業が運営している公式のボットですがLINEボットは個人でも作成が可能となっています。
Cloud Vision APIとは
パワフルな画像分析
Google Cloud Vision API を利用すると、使いやすい REST API でカプセル化されたパワフルな機械学習モデルにより画像内容を理解できるようになります。Google Cloud Vision API は、膨大な数のカテゴリ(「ヨット」や「ライオン」、「エッフェル塔」など)に各画像を素早く分類する機能や、画像内の個々の物体や人の顔を検出する機能、画像内に含まれているテキストを検出して読み取る機能を備えています。また、画像カタログのメタデータ作成、不適切なコンテンツの管理、画像の感情分析を通じた新しいマーケティング手法の導入が可能になります。リクエストに含めてアップロードした画像を分析することも、Google Cloud Storage の画像ストレージと統合することもできます。
Googleが提供している画像解析のAPIです。OCRだけでなく、画像解析全般に対応しており、顔認識やランドマークの検出など多岐に行えます。
画像内のさまざまな物体を簡単に検出して、花、動物、乗り物など、画像によく含まれている何千もの物体カテゴリに分類することができます。新しいコンセプトが導入されるたびに精度が向上していくため、Vision API の性能は時がたつにつれて高まっていきます。
参考:https://cloud.google.com/vision/
文字起こしで利用するOCRは公式サイトでは「テキスト抽出」となっており、多言語に置いて利用可能です。
Vision API は、光学式文字認識(OCR)機能を備えており、画像内のテキストを検出することが可能です。言語の種類も自動で判別され、さまざまな言語が幅広くサポートされています。
参考:https://cloud.google.com/vision/
利用料金も無料のプランから通信回数に応じて料金が発生するようになっています。
ただし、課金しない限りは勝手に料金が発生することは無いので安心して使えます。(利用回数上限に達するとAPIが使えなくなります。) ※参考:Google Cloud Vision 料金
※参考:Google Cloud Vision 料金
Computer Vision APIとは
画像から豊富な情報を抽出して、視覚データを分類および処理します。また、機械による画像のモデレートを実施して、サービスのキュレーションを支援します。
公式サイトから引用していますが、これ見るだけだと何がなんだかわかりませんが、Microsoftが提供している画像解析のAPIです。
Googleとの差異としては、MicrosoftはFace APIという顔認識に特化したAPIも提供しており、そのAPIを利用すると画像に写っている人の年齢や性別、髪の毛の長さなどの判定や表情から感情を分析する「感情分析」が利用可能です。
顔認識の判定はGoogleより広い範囲で対応している印象です。こちらのAPIも使い方は簡単なのでまた別途紹介します。
料金設定も無料アカウントでも毎月一定数は利用可能です。Googleと同じですね。有料プランだとトランザクション数に応じて従量課金性になっています。
 ※参考:Cognitive Services の価格 – Computer Vision API
※参考:Cognitive Services の価格 – Computer Vision API文字起こしボットの仕組み(ロジック)
とタラタラとLINEボットやOCRのAPIについて説明しましたが、ここからようやく本題です。テキスト抽出には上記のAPIを利用していますが、それをLINEボットから呼び出している仕組みについて紹介していきます。
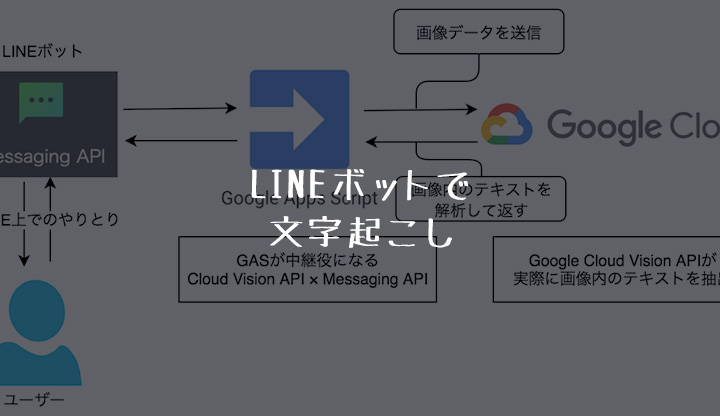
Messaging APIとGASを利用したリプライ型ボット
まず、LINEボットの大枠ですが、以前にも紹介しているGAS(Google Apps Script)を利用したリプライ型ボットになります。
 【LINE Botの作り方】Messaging API × GAS(Google Apps Script)でおうむ返しボットを作成する
大まかな流れは以下の図の通りです。
【LINE Botの作り方】Messaging API × GAS(Google Apps Script)でおうむ返しボットを作成する
大まかな流れは以下の図の通りです。

リプライ型のLINEボットを作成するときはGASを使用するのが非常に手軽で良いです。GASからたいていのAPIは利用することができるし、Spread Sheetと連携させれば簡単なDBを持ったような実装を行うことができます。
プッシュ通知型の場合はCloud9とPythonとかが良いですね。Cloud9はCloud上のIDEであり、コーディングからサーバーとしての実行まで一括で行えてしまいます。また、ブラウザ上で扱えるためどこのPCからでも環境にアクセスが可能です。
以前に紹介したプッシュ通知のLINEボットもCloud9での実装をしています。
 【LINE Botの作り方】Python × Messaging APIでプッシュ通知を行うボットを作ろう
【LINE Botの作り方】Python × Messaging APIでプッシュ通知を行うボットを作ろう
画像の形式変換だけが最大の壁
実際に実装をしていてつまづいたのがGASからCloud Vision APIに画像を送信する場面です。JavascriptとかWeb開発に慣れている方であればおそらくすんなり実装可能なのでしょうが、Web開発初心者にはちょっとハードルが高めでした。(普段はサーバーサイドエンジニアでJava使ってます。)
Cloud Vision APIに画像を送信する際には決まった形式で画像データを渡してあげる必要があります。具体的には以下の3パターンです。
- base64 エンコード文字列
- Google Cloud Storage URI
- ウェブ URL
※Google Cloud Storageというのはそのまんまですが、Googleのストレージサービスです。Googleドライブをよりビジネス面で強化したようなものだと考えてください。(違うかも)
※ウェブURLもそのままですね。「https://*****.jpg」などの画像に直接アクセスできるURLを指します。
最初はCloud VisionがGoogleのサービスなので同様にCloud Storageを使用しようとしたのですが、Cloud Storageに画像保存するためにはOAuth認証(※)が必要なことがわかりました。OAuth認証のサンプルソースなどもあり、ロジック上で実装してしまえばそれだけなのですが、ソースコード量も多くなってしまいます。画像データ渡すだけならもっと簡単な方法があるだろうと考え、一旦Google Storageの使用は諦めました。
※OAuth認証はGoogleのログイン認証機能のこと。
続いてbase64エンコードを検討しました。GASには便利な標準ライブラリがついており、そこにbase64エンコードの処理もあったためこれ使えるんじゃないかと思い実装してみました。
Utilities.base64Encode('base64にエンコードするデータを指定')
一度Blob形式に変換したりもしましたが、どうにも上手くいかずここでかなり時間を使ってしまいました。
Googleドライブに一時的に保存することで解決
いろんな形式の画像で試してみたのですが、どうやらGoogleドライブに保存した画像データであれば、それを取り出してbase64エンコードかますことでAPIが反応してくれることがわかりました。
GASからSpread Sheetが数行で扱えるのと同様にGoogleドライブも簡単に扱えます。ファイルを保存するだけなら2行でかけてしまいます。お手軽。
var myFolder = DriveApp.getFolderById('GoogleドライブのフォルダID指定');
myFolder.createFile('保存するデータ指定'.setName('保存するファイル名指定'));
※人様の画像保存しておくとプライバシー云々やら、単純に保存容量の圧迫などがあるので基本的には画像は一時保存でしっかり消しましょう。
GASから各種APIの呼び出しを行う
GASからCloud Visionなどを呼び出すのですが、これはリファレンスに記載されている通りに記述するだけです。
下記に記載したエンドポイントに対してPOST通信でリクエストを投げてあげれば解析した結果が返ってきます。
POST https://vision.googleapis.com/v1/images:annotate?key=YOUR_API_KEY
{
"requests": [
{
"image": {
"content": "/9j/7QBEUGhvdG9zaG9...base64-encoded-image-content...fXNWzvDEeYxxxzj/Coa6Bax//Z"
},
"features": [
{
"type": "TEXT_DETECTION"
}
]
}
]
}
{
"responses": [
{
"textAnnotations": [
{
"locale": "en",
"description": "Wake up human!\n",
"boundingPoly": {
"vertices": [
{
"x": 29,
"y": 394
},
{
"x": 570,
"y": 394
},
{
"x": 570,
"y": 466
},
{
"x": 29,
"y": 466
}
]
}
},
{
"description": "Wake",
"boundingPoly": {
"vertices": [
{
"x": 29,
"y": 394
},
{
"x": 199,
"y": 394
},
{
"x": 199,
"y": 466
},
{
"x": 29,
"y": 466
}
]
}
},
{
"description": "up",
"boundingPoly": {
"vertices": [
{
"x": 226,
"y": 394
},
{
"x": 299,
"y": 394
},
{
"x": 299,
"y": 466
},
{
"x": 226,
"y": 466
}
]
}
},
{
"description": "human!",
"boundingPoly": {
"vertices": [
{
"x": 320,
"y": 394
},
{
"x": 570,
"y": 394
},
{
"x": 570,
"y": 466
},
{
"x": 320,
"y": 466
}
]
}
}
]
}
]
}
まとめ
Cloud Vision APIが公開されたのは数年前なので今更感はありますが、機械学習がここまで手軽に利用できるのは驚異的ですね。。
実際にOCRや顔認証のAPIなどをちょくちょくお試しで使っていますが、一部微妙なところもありますが、全体的に精度は高い印象です。特に文字起こしで使用するOCRの精度はかなり高いですね。
OCRの精度は感覚だと、Google > Microsoft と言ったところです。なので今回も結局Google Cloud Vision APIの解説がほぼでしたがGoogleのAPIを利用するのがオススメです。今んとこは。
そしてこのLINE BotとかGoogleのAPIを利用してアプリを作成するというのはこれからプログラミングをやってみたいと考えている方にはかなりオススメです。最初は既に作られているものを真似するだけでも良いのでとにかく一つ作ってみることをオススメします。
今回紹介したLINEボットで文字起こしはAPI料金なども発生せず無料で作成可能なのでぜひ試してみてください。
実際のソースコードなどは以下のnoteで公開しています。

